ProVision | Multimodal Instruction Data Generation
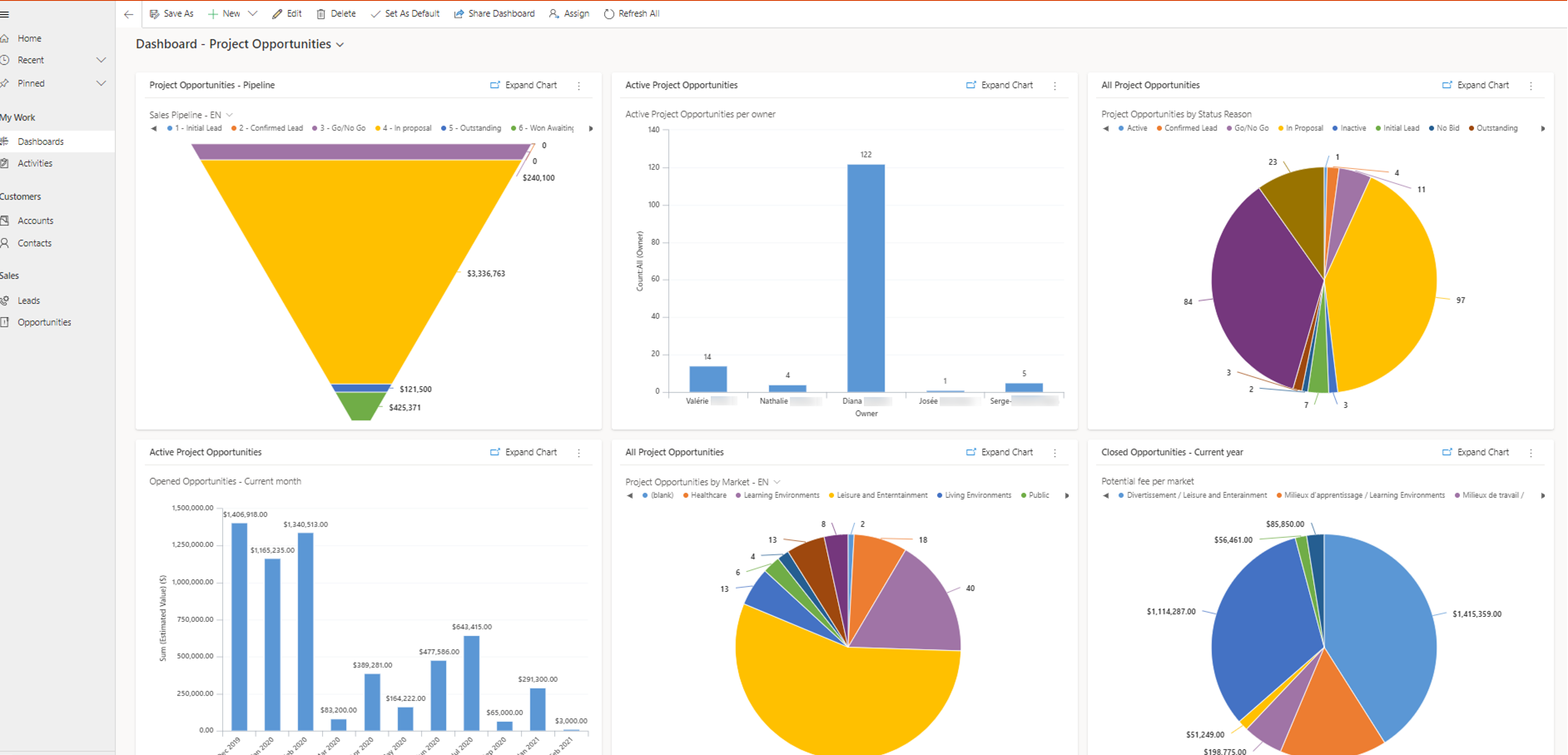
Introduction The development of multimodal language models (MLMs) such as GPT4-V and BLIPs [1,2] have enabled many multimodal applications such as answering complex image-based queries; for example, “How many students are raising their hands in this image?”. These models rely heavily on instruction data—datasets that